缓存
为什么要用缓存(缓存的优点)
- 缓存减少了冗余的数据传输,节省了你的网络费用
- 缓存缓解了网络瓶颈的问题。不需要更多的带宽就能够更快地加载页面
- 很多网络为本地客户端提供的带宽远比为远程服务器提供的带宽要宽(100M/1.4M)
- 缓存降低了对原始服务器的要求,服务器可以更快地响应,避免过载的出现
- 缓存在破坏瞬间拥塞的时候显得非常重要
- 缓存降低了距离时延,因为从较远的地方加载页面会更慢一些
- 即使使用并行的持久连接,中等复杂的Web页面会带来几秒钟的光速时延
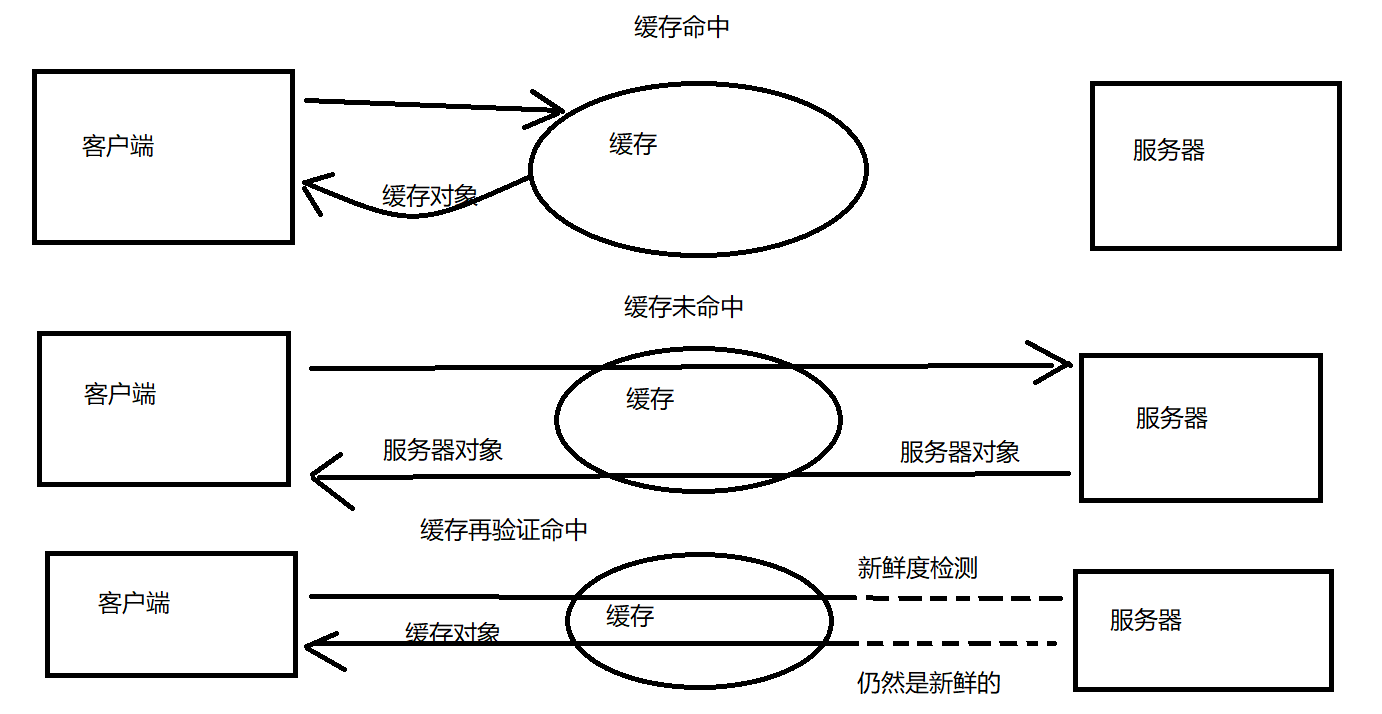
命中和未命中
缓存无法保存世界上每份文档的副本
已有的副本为某些到达缓存的请求提供服务,称为缓存名中
而其他的请求被转发给原始服务器,称为缓存未命中
再验证
原始服务器的内容可能会发生变化,缓存要时不时对其进行检测,看它们是否是服务器上最新的副本
缓存可以在任意时刻,以任意的频率对副本进行再验证,一般只有在副本旧得足以需要检测的时候才会对副本进行再验证
缓存对缓存的副本进行再验证时,会向原始的服务器发送一个小的再验证请求
- 如果内容没有变化,服务器会以一个小的304 Not Modified进行响应,被称为再验证命中或缓慢命中
- 如果服务器对象已与缓存副本不同,服务器向客户端发送一条普通的、带有完整内容的http 200 ok响应
- 如果服务器对象已经被删除了,服务器返回一个404 Not Found响应,缓存也会被副本删除
1 | |
命中率和字节命中率
命中率:由缓存提供服务所占比例
字节命中率:有些大文件,可能访问的次数少,但是一次访问对数据流量的贡献很大,指缓存提供的字节在传输的所有字节中提供的比例
区分命中和未命中
通过Date首部(日期值较早则命中)以及Age首部来判断
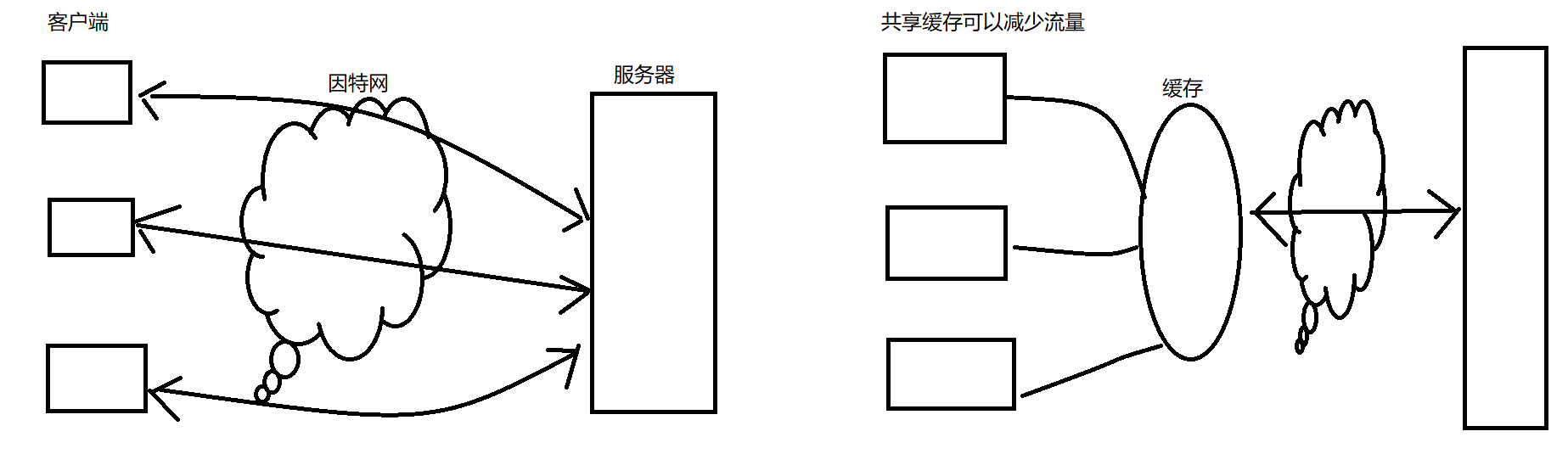
缓存的拓扑结构
私有缓存与公有代理缓存
共享缓存可以减少流量
代理缓存的层次结构
像树一样从底部到顶部依次向更高级的缓存去寻找资源判断是否命中
缓存的处理步骤
1)接收——缓存从网络中读取抵达的请求报文
2)解析——缓存对报文进行解析,提取出URL和各种首部
3)查询——缓存查看是否有本地副本可用,如果没有,就获取一份副本(并将其保存在本地)
4)新鲜度检测——缓存查看已缓存副本是否足够新鲜,如果不是,就询问服务器是否有任何更新
5)创建响应——缓存会用新的首部和已缓存的主体来构建一条响应报文
6)发送——缓存通过网络将响应发回给客户端
7)日志——缓存可选地创建一个日志文件条目来描述这个事务
缓存
https://blog-theta-ten.vercel.app/2021/10/15/缓存/